I am currently a Master’s of Computer Science at Rice University with have strong background in integrating technology with diverse fields.
Born and raised in Taiwan, I am fluent in both Mandarin and English, which enriches my ability to navigate and contribute to global tech discussions. I am excited about leveraging my interdisciplinary background to drive innovation at the intersection of technology and various domains.
You can see some of my work in the following section and in the "selected projects" page as well.
What I do:
LLM orchestration & RAG: LangChain pipelines, retrieval with vector DBs (Pinecone/Chroma), prompt engineering/evaluation, tool/function calling, routing, observability, and production deployment.
Model fine-tuning: Transfer learning with LoRA/PEFT, dataset curation/cleaning, validation and ablation, metrics-driven evaluation, and safety/quality checks.
Training from scratch (PyTorch): Custom architectures, losses and optimizers, data preprocessing/augmentation, experiment tracking, and performance tuning.
Where I've applied it: Vision-language assistants, static code analysis/fixing, and anomaly detection with GNNs; plus time-series forecasting.
Mar–May 2025 · Team project (lead on data/model) · Houston, TX
Built an image-aware Q&A assistant for artworks: crawler → metadata → auto Q&A → adapter-tuned VLM → evaluation → demo.
Jul–Aug 2025 · Software Engineering Intern · Taipei, Taiwan
Automated part of static-analysis fixing: parse issues → propose patch → test → open PR.
Jan–May 2024 · Undergrad thesis · Beijing, China
Combined feature models with a GAT to flag suspicious nodes in a Bitcoin-like graph.
My academic journey began at Peking University’s YuanPei College, where I majored in Data Science. My love for integrating technology with diverse fields led me to explore groundbreaking projects, such as using graph neural networks(GCN and GAT) for anomaly detection in Bitcoin during my undergraduate thesis.
Recognizing that emerging technologies like AI are deeply rooted in fundamental computer science principles, I am currently pursuing a Master’s degree in Computer Science at Rice University. Here, I am diving into core areas such as database implementation network and operating system. Below are some of my projects that I done during my graduate studies.
Aug–Dec 2024 · Team of two · Rice University
Built core DBMS parts on Linux: page cache with LRU, on-disk B+-tree, and a minimal SQL front end.
Oct 2025 – present · Solo project · Taipei, Taiwan
Web + mobile app for reviews, search, and watchlist. Secure auth, paginated APIs, and clean UI.
Mar–Sep 2023 · Team (first author) · Beijing, China
Estimated demand and optimized (R,S) to hit ~80% service level at lower cost.
This case study focuses on establishing an efficient (R, S) inventory management model for the beverage supply chain, considering multiple stock-keeping units(SKUs) and dynamic shifts in demand. The primary objective is to determine safety stock levels (S) for each SKU to ensure the stability and reliability of the supply chain. Utilizing classification, periodicity analysis, machine learning forecasting, and model refinement, I established a comprehensive inventory management model. This model requires annual updates following a quarterly pattern, ensuring effective inventory management and offering substantial support and guidance for supply chain management, with potentially significant economic benefits in practice.
This Kaggle project tackles healthcare fraud by analyzing a synthetic dataset of medical claims. The data, split into patient, provider, claim, and payment files, is first cleaned and merged. The core task is a classification problem: identifying potentially fraudulent providers. I performed exploratory data analysis (EDA) to uncover suspicious patterns, such as excessive billing or unusual claim frequencies. Finally, various machine learning models (like Random Forest or gradient boosting) are trained on engineered features (e.g., average claim amount per provider) to predict fraud, with a focus on metrics like recall and F1-score due to the imbalanced nature of the data.
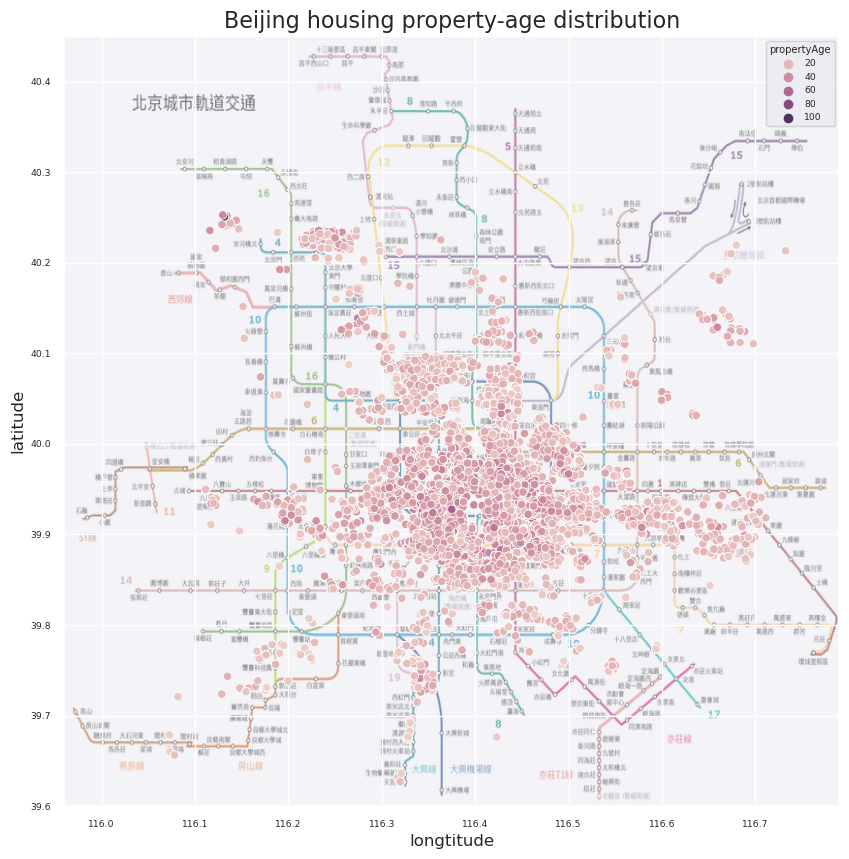
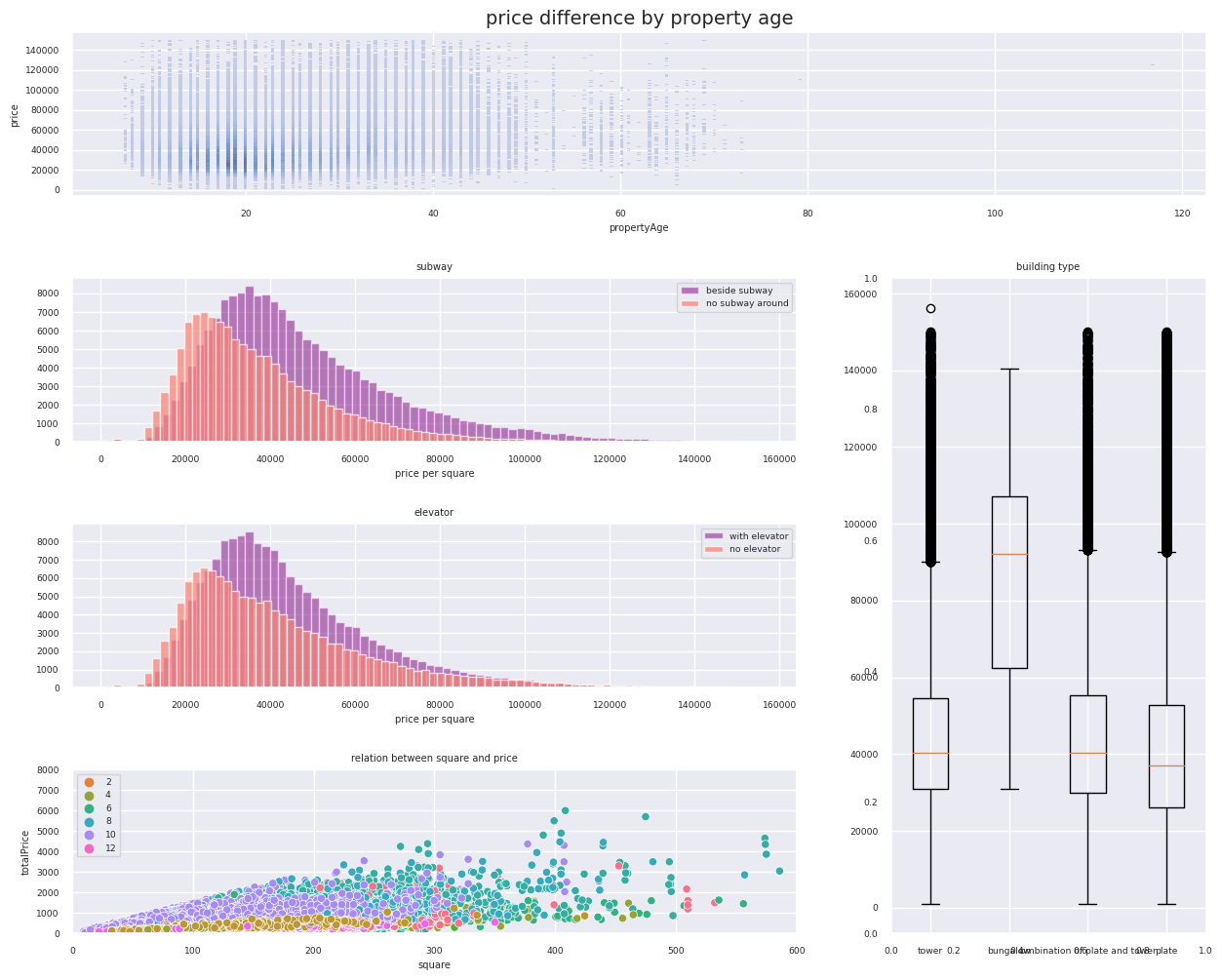
In this project, I focused on exploratory data analysis (EDA) using Python. I utilized the matplotlib and seaborn libraries to visualize a dataset from lianjia.com, which contains 318,851 housing transactions in Beijing from 2013 to 2017. The analysis explores 26 features, including price, size, location, decoration, and "Days on Market" (DOM). The primary goal is to practice visualization techniques and uncover trends within the Beijing real estate market, such as the relationship between property attributes and transaction prices.
Overview: The AI-Powered Video Analyzer is a web application designed to make video learning smarter, faster, and more engaging. Instead of passively watching long videos, users can interact with the content using AI-driven tools that summarize, quiz, and explain key moments — helping them retain information more effectively. This project integrates Gemini API to analyze video transcripts, extract important insights, and generate personalized learning materials — all within an intuitive, minimal UI.
Key Features:AI Summarization – Get concise takeaways from any educational or informational video.
Auto Quizzes & Flashcards – Test your understanding instantly with AI-generated questions.
Smart Notes with Timestamps – Add notes tied to specific video moments and ask the AI to elaborate.
Context-Aware Explanations – Click “Explain” to receive targeted clarifications based on the current section.
Learning History – Track watch time, quiz results, and personal progress in your browser. Watch a demonstration of my application development project.
The application is a client-side, single-page web application built with React. It functions as an agent by combining user-driven intent with the powerful multimodal and function-calling capabilities of the Gemini API to provide interactive analysis of video content.